There is a lot of recent focus on “developer productivity” as it relates to the divide between application developers, DevOps, and the “newish” platform engineering concept.
At the end of the day, some folks want to write code, some just want to make the code someone else wrote run in production, and some want to straddle both domains.
But common to everyone is the need to unlock developer productivity. One way to do that is to understand the “hidden tax” config sprawl plays in slowing down team velocity.
It’s a “productivity drain” hiding in plain sight and the root cause of unplanned work in the form of excess outages, extended time to recover from an outage and remediate security incidents.
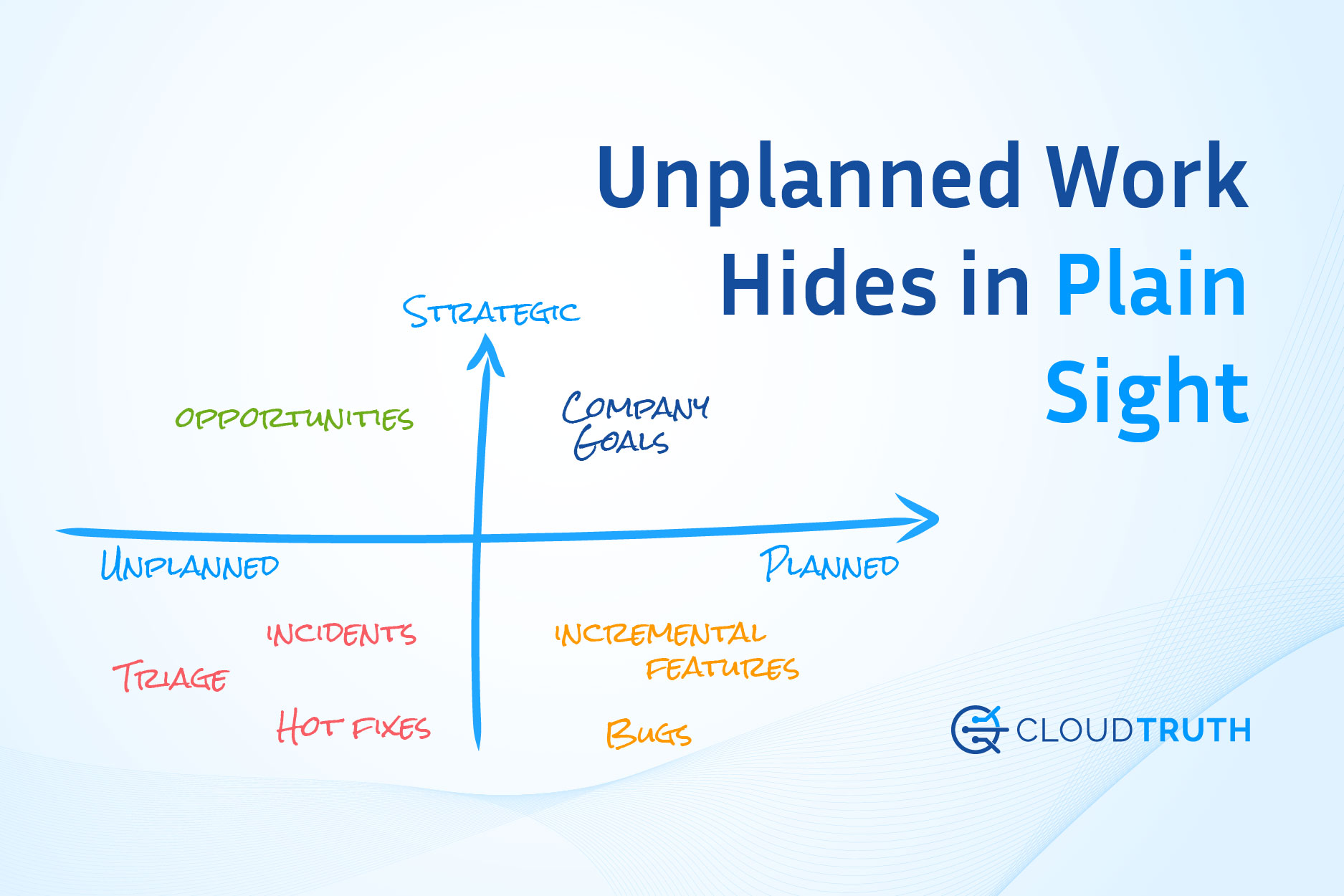
What is Unplanned Work?
Every engineer, manager, and C-level person has experienced unplanned work. Whether it’s an emergency that pops up or day-to-day tasks that haven’t been adequately automated yet, unplanned interferes with planned work and ultimately achieving team and organizational goals.
Per Google’s SRE Handbook, an engineer should spend no more than 50% of their day on unplanned work, or in other words, “putting out fires.” It is time-consuming and never stops until the team works together to create repeatable processes.
Whether it is:
- Alerts that continuously occur.
- Manual deployments.
- Manual infrastructure/cloud service management. Much unplanned work comes from misconfigurations and improper use of configuration data.
75% percent of the time, unplanned work traces back to misconfigurations and improper configuration data management
Ensure Engineering and Management are Aligned
The first and most important step toward minimizing unplanned work is to ensure that engineering and management are on the same page. There is precisely zero technology that can fix a problem if the culture is terrible.
Consider this common scenario:
The leadership team learns about a new technology or platform. Something that is supposed to be cutting-edge and solve a specific problem the organization is having. After many sales calls, senior leadership wants the new technology because they have been told it is easy to implement and will solve many problems.
When engineering is finally consulted, they explain that it’s not an easy lift and will take months to implement due to factors not obvious to leadership fully. The leadership team doesn’t like that answer and pushes to move forward. The engineering team is forced to get the new platform up and running and, in the process, cuts corners, which results in an unstable platform and a deteriorating relationship between management and engineering.
It shouldn’t happen if management and engineering are on the same page, which should be fixed before implementing technology.
Minimize Fire Fighting and Context Switching
As mentioned in the opening of this blog post, the Google SRE Handbook states that no engineer should spend more than 50% of their time putting out fires. This includes:
- Fixing alerts
- Manually deploying infrastructure
- Manually deploying cloud services
- Manually deploying apps
- SSHing or RDPing into a server to fix it
and anything else that isn’t a repeatable process.
The other 50% of an engineer’s time, depending on their role (like a Platform Engineer,) should be spent automating repeatable processes. That way, the 50% they’re spending on fires turns into 20%, or lower if possible.
With engineering spending more time figuring out how to automate putting out fires instead of manually doing it, they open their time up for more value-driven work and features that help the platform and, ultimately, the organization grows. It’s the perfect plan to ensure that you’re staying ahead of the competition and so engineers don’t burn out.
Manage Configuration Data Properly
The third tip is to ensure that wherever you’re managing your configuration data, it’s done right.
Parameters, variables, secrets, and other configuration data are spread across many places. A little in a cloud-based service, a little in CICD pipeline variables, and more in source control. There’s far too much data to spread all over the place.
Better yet, there’s far too much data not to be managed by one location.
Can you have your data in different locations? Yes, but you need one place you can go to. Whether it’s to read the data, to make changes, or for confirmation, there must be a place that holds or automatically retrieves data for you without you having to check (what feels like) a million different locations.
Much toils and putting out fires for engineering teams stem from having configuration data stored in multiple locations, and some solutions can help with this.
Wrapping Up
The whole idea behind CloudTruth is to mitigate as many of these problems as possible. The reality is CloudTruth can’t reduce all of them, but the platform can undoubtedly mitigate north of 90% of them.
You can check out CloudTruth for free here, the CloudTruth Quick Start Videos, and the blog for more tips on increasing deployment velocity and reliability with centralized config.
Join ‘The Pipeline’
Our bite-sized newsletter with DevSecOps industry tips and security alerts to increase pipeline velocity and system security.